

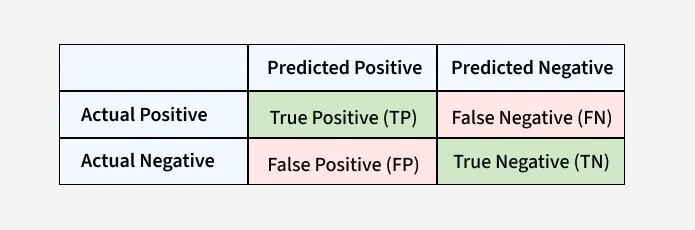
La matrice de confusion est un tableau simple utilisé pour mesurer les performances d'un modèle de classification. Il compare les prédictions faites par le modèle avec les résultats réels et montre où le modèle était vrai ou faux. Cela vous aide à comprendre où le modèle fait des erreurs afin que vous puissiez l'améliorer. Il répartit les prédictions en quatre catégories :
- Vrai positif (TP) : Le modèle a correctement prédit un résultat positif, c'est-à-dire que le résultat réel était positif.
- Vrai négatif (TN) : Le modèle a correctement prédit un résultat négatif, c'est-à-dire que le résultat réel était négatif.
- Faux positif (FP) : Le modèle a prédit à tort un résultat positif, c'est-à-dire que le résultat réel était négatif. Elle est également connue sous le nom d’erreur de type I.
- Faux négatif (FN) : Le modèle a prédit à tort un résultat négatif, c'est-à-dire que le résultat réel était positif. Elle est également connue sous le nom d’erreur de type II.
Il permet également de calculer des mesures clés telles que précision, précision et rappel ce qui donne une meilleure idée des performances surtout lorsque les données sont déséquilibrées.

Métriques basées sur les données de la matrice de confusion
1. Précision
Précision montre combien de prédictions le modèle a obtenu à partir de toutes les prédictions. Cela donne une idée de la performance globale mais cela peut être trompeur lorsqu'une classe est plus dominante que l'autre. Par exemple, un modèle qui prédit correctement la classe majoritaire la plupart du temps peut avoir une grande précision mais ne parvient toujours pas à capturer des détails importants sur les autres classes. Il peut être calculé à l'aide de la formule ci-dessous :
\text{Précision} = \frac {TP+TN}{TP+TN+FP+FN}
2. Précision
Précision se concentrer sur la qualité des prédictions positives du modèle. Cela nous indique combien de prédictions « positives » étaient réellement correctes. Ceci est important dans les situations où les faux positifs doivent être minimisés, comme par exemple pour détecter les spams ou les fraudes. La formule de précision est :
\text{Précision} = \frac{TP}{TP+FP}
3. Rappel
Rappel mesure la capacité du modèle à prédire les positifs. Il montre la proportion de vrais positifs détectés parmi toutes les instances positives réelles. Un rappel élevé est essentiel lorsque l’absence de cas positifs a des conséquences importantes, comme dans le cas des tests médicaux.
\text{Rappel} = \frac{TP}{TP+FN}
4. Score F1
Score F1 combine précision et rappel en une seule mesure pour équilibrer leur compromis. Il donne une meilleure idée des performances globales d'un modèle, en particulier pour les ensembles de données déséquilibrés. Il est utile lorsque les faux positifs et les faux négatifs sont importants, même s'il suppose que la précision et le rappel sont tout aussi importants, mais dans certaines situations, l'un peut être plus important que l'autre.
\text{F1-Score} = \frac {2 \cdot Precision \cdot Recall}{Précision + Rappel}
5. Spécificité
Spécificité est une autre mesure importante dans l'évaluation des modèles de classification, en particulier dans la classification binaire. Il mesure la capacité d'un modèle à identifier correctement les instances négatives. La spécificité est également connue sous le nom de formule du taux vrai négatif. Elle est donnée par :
\text{Spécificité} = \frac{TN}{TN+FP}
6. Erreur de type 1 et de type 2
Types 1 et Types 2 les erreurs sont :
- Erreur de type 1: Cela se produit lorsque le modèle prédit incorrectement une instance positive mais que l'instance réelle est négative. Ceci est également connu sous le nom de faux positif. Les erreurs de type 1 affectent le précision d'un modèle qui mesure l'exactitude des prédictions positives.
\text{Erreur de type 1} = \frac{\text{FP}}{\text{FP} + \text{TN}}
- Erreur de type 2: Cela se produit lorsque le modèle ne parvient pas à prédire une instance positive même si elle est réellement positive. Ceci est également connu sous le nom de faux négatif. Les erreurs de type 2 ont un impact sur rappel d'un modèle qui mesure dans quelle mesure le modèle identifie tous les cas positifs réels.
\text{Erreur de type 2} = \frac{FN}{TP+FN}
Exemple: Un test de diagnostic est utilisé pour détecter une maladie particulière chez les patients.
- Erreur de type 1 (faux positif) : Cela se produit lorsque le test prédit qu'un patient est atteint de la maladie (résultat positif) alors que le patient est en réalité en bonne santé (cas négatif).
- Erreur de type 2 (faux négatif) : Cela se produit lorsque le test prédit que le patient est en bonne santé (résultat négatif) alors que le patient est réellement atteint de la maladie (cas positif).
Matrice de confusion pour la classification binaire
Une matrice de confusion 2×2 est présentée ci-dessous pour la reconnaissance d'image ayant une image de chien ou une image de non-chien :
| Prédit | Prédit | |
|---|---|---|
| Réel | Vrai positif (TP) | Faux négatif (FN) |
| Réel | Faux positif (FP) | Vrai négatif (TN) |
- Vrai positif (TP) : Ce sont les décomptes totaux ayant à la fois des valeurs prédites et réelles qui constituent Dog.
- Vrai négatif (TN) : Ce sont les décomptes totaux ayant à la fois des valeurs prédites et réelles qui ne sont pas des chiens.
- Faux positif (FP) : Il s'agit du nombre total de prédictions indiquant qu'il s'agit d'un chien alors qu'en réalité ce n'est pas un chien.
- Faux négatif (FN) : C'est le nombre total dont la prédiction est « Pas un chien » alors qu'en réalité, c'est un chien.
Exemple : Matrice de confusion pour la reconnaissance d'images de chiens avec des chiffres
|
Indice |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|---|---|---|---|---|---|---|---|---|---|---|
|
Réel |
Chien |
Chien |
Chien |
Pas un chien |
Chien |
Pas un chien |
Chien |
Chien |
Pas un chien |
Pas un chien |
|
Prédit |
Chien |
Pas un chien |
Chien |
Pas un chien |
Chien |
Chien |
Chien |
Chien |
Pas un chien |
Pas un chien |
|
Résultat |
TP |
FR |
TP |
TN |
TP |
FP |
TP |
TP |
TN |
TN |
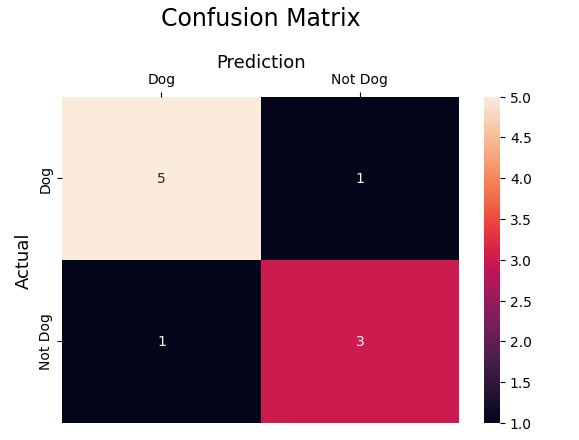
- Nombre réel de chiens = 6
- Nombre réel de chiens non = 4
- Nombres vrais positifs = 5
- Nombre de faux positifs = 1
- Nombres vrais négatifs = 3
- Nombre de faux négatifs = 1
|
|
Prédit |
||
|---|---|---|---|
|
Chien |
Pas un chien |
||
|
Réel |
Chien |
Vrai positif |
Faux négatif |
|
Pas un chien |
Faux positif |
Vrai négatif |
|
Implémentation de la matrice de confusion pour la classification binaire à l'aide de Python
Étape 1 : Importez les bibliothèques nécessaires
import numpy as np
from sklearn.metrics import confusion_matrix,classification_report
import seaborn as sns
import matplotlib.pyplot as plt
Étape 2 : Créez le tableau NumPy pour les étiquettes réelles et prévues
- réel: représente les véritables étiquettes ou la classification réelle des éléments. Dans ce cas, il s'agit d'une liste de 10 éléments dont chaque entrée est soit « Chien » soit « Pas chien ».
- prédit : représente les étiquettes prédites ou la classification effectuée par le modèle.
actual = np.array(
['Dog','Dog','Dog','Not Dog','Dog','Not Dog','Dog','Dog','Not Dog','Not Dog'])
predicted = np.array(
['Dog','Not Dog','Dog','Not Dog','Dog','Dog','Dog','Dog','Not Dog','Not Dog'])
Étape 3 : Calculer la matrice de confusion
- matrice_de confusion : Cette fonction de sklearn.metrics calcule la matrice de confusion qui est un tableau utilisé pour évaluer les performances d'un algorithme de classification. Il compare le réel et le prévu pour générer une matrice
cm = confusion_matrix(actual,predicted)
Étape 4 : Tracez la matrice de confusion à l'aide de la carte thermique Seaborn
- sns.heatmap : Cette fonction de Né de la mer est utilisé pour créer une carte thermique de la matrice de confusion.
- pas=Vrai : Affichez les valeurs numériques dans chaque cellule de la carte thermique.
sns.heatmap(cm,
annot=True,
fmt='g',
xticklabels=['Dog','Not Dog'],
yticklabels=['Dog','Not Dog'])
plt.ylabel('Actual', fontsize=13)
plt.title('Confusion Matrix', fontsize=17, pad=20)
plt.gca().xaxis.set_label_position('top')
plt.xlabel('Prediction', fontsize=13)
plt.gca().xaxis.tick_top()
plt.gca().figure.subplots_adjust(bottom=0.2)
plt.gca().figure.text(0.5, 0.05, 'Prediction', ha='center', fontsize=13)
plt.show()
Sortir:
Étape 5 : Rapport de classification basé sur les mesures de confusion
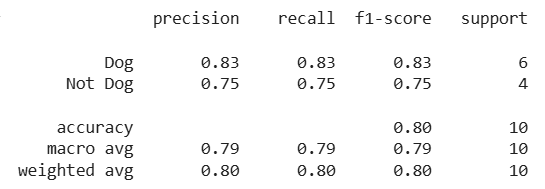
print(classification_report(actual, predicted))
Sortir:
Matrice de confusion pour la classification multiclasse
Dans classification multiclasse la matrice de confusion est étendue pour tenir compte de plusieurs classes.
- Lignes représentent les classes réelles (vérité terrain).
- Colonnes représentent les classes prédites.
- Chaque cellule de la matrice indique la fréquence à laquelle une classe réelle spécifique a été prédite comme une autre classe.
Par exemple, dans un problème à 3 classes, la matrice de confusion serait un tableau 3×3 où chaque ligne et colonne correspond à l'une des classes. Il résume les performances du modèle dans toutes les classes dans un format compact. Considérons l'exemple ci-dessous :
Exemple : Matrice de confusion pour la classification d'images (chat, chien, cheval)
| Réel\Prévu | Chat prédit | Chien prévu | Cheval prédit |
|---|---|---|---|
| Chat réel | Correct | Mal classé | Mal classé |
| Chien réel | Mal classé | Correct | Mal classé |
| Cheval réel | Mal classé | Mal classé | Correct |
Note: Dans la classification multiclasse, les valeurs hors diagonale représentent des erreurs de classification.
Pour une classe donnée, une instance mal classée agit comme un faux négatif (FN) pour la classe réelle et un faux positif (FP) pour la classe prédite. Par conséquent, FP et FN sont définis par classe et non par cellule.
Exemple avec des nombres :
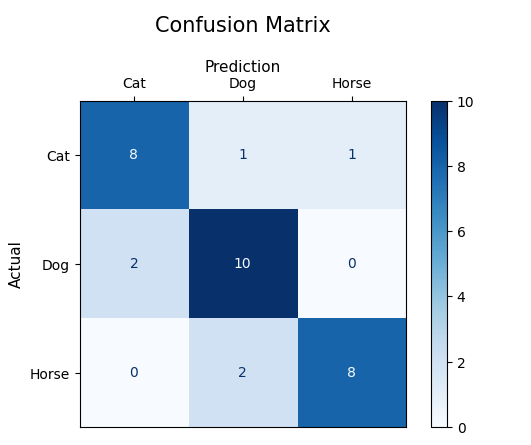
Lors de l'évaluation d'une classe à la fois (un contre repos), les mesures de la matrice de confusion telles que TP, FP, FN et TN sont calculées séparément pour chaque classe. Considérons le scénario dans lequel le modèle traite 30 images :
| Chat prédit | Chien prévu | Cheval prédit | |
|---|---|---|---|
| Chat réel | 8 | 1 | 1 |
| Chien réel | 2 | 10 | 0 |
| Cheval réel | 0 | 2 | 8 |
Dans ce scénario :
- Chats : 8 ont été correctement identifiés, 1 a été identifié à tort comme un chien et 1 a été identifié à tort comme un cheval.
- Chiens : 10 ont été correctement identifiés, 2 ont été identifiés à tort comme des chats.
- Chevaux: 8 ont été correctement identifiés, 2 ont été identifiés à tort comme des chiens.
Pour calculer les vrais négatifs, nous devons connaître le nombre total d’images qui ne sont PAS des chats, des chiens ou des chevaux. Supposons qu'il y ait 10 images de ce type et que le modèle les a toutes correctement classées comme « pas de chat », « pas de chien » et « pas de cheval ». Donc:
- Nombre de vrais négatifs (TN) : 10 pour chaque classe car le modèle a correctement identifié chaque image autre qu'un chat/un chien/un cheval comme n'appartenant pas à cette classe
Implémentation de Confusion Matrix pour la classification multi-classe à l'aide de Python
Étape 1 : Importez les bibliothèques nécessaires
import numpy as np
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay, classification_report
import matplotlib.pyplot as plt
Étape 2 : Créez le tableau NumPy pour les étiquettes réelles et prévues
- y_vrai : Liste des vraies étiquettes.
- y_pred : Liste des étiquettes prédites par le modèle.
- cours : Une liste de noms de classes : « Chat », « Chien » et « Cheval »
y_true = ['Cat'] * 10 + ['Dog'] * 12 + ['Horse'] * 10
y_pred = ['Cat'] * 8 + ['Dog'] + ['Horse'] + ['Cat'] * 2 + ['Dog'] * 10 + ['Horse'] * 8 + ['Dog'] * 2
classes = ['Cat', 'Dog', 'Horse']
Étape 3 : générer et visualiser la matrice de confusion
- ConfusionMatrixAffichage : Crée un objet d'affichage pour la matrice de confusion.
- confusion_matrix=cm : Passe la matrice de confusion (
cm) à afficher. - display_labels=classes : Définit les étiquettes ([‘Cat’ , ‘Dog’ , ‘Horse’]) ou la matrice de confusion.
cm = confusion_matrix(y_true, y_pred, labels=classes)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=classes)
disp.plot(cmap=plt.cm.Blues)
plt.title('Confusion Matrix', fontsize=15, pad=20)
plt.xlabel('Prediction', fontsize=11)
plt.ylabel('Actual', fontsize=11)
plt.gca().xaxis.set_label_position('top')
plt.gca().xaxis.tick_top()
plt.gca().figure.subplots_adjust(bottom=0.2)
plt.gca().figure.text(0.5, 0.05, 'Prediction', ha='center', fontsize=13)
plt.show()
Sortir:
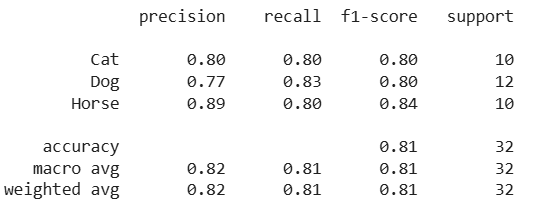
Étape 4 : Imprimer le rapport de classification
print(classification_report(y_true, y_pred, target_names=classes))
Sortir:
La matrice de confusion fournit des informations claires sur des mesures importantes telles que l'exactitude, la précision et le rappel en analysant les prédictions correctes et incorrectes.

